Nim Metaprogramming - Macro Tutorial
This tutorial aims to be a step-by-step introduction to the metaprogramming features of the Nim Language and to provide as much detail as possible to kickstart your most complex projects. There are already many resources on the Web, but I strive to provide more thorough details on the development process and to gather them all in one place.
⚠️ This tutorial is still under heavy development.
Table of Contents:
- Introduction
- Generics
- Templates
- Macros
- For loop
typedParameters- Hygienic variables
- Avoiding Macros
- References and Bibliography
Introduction
Four levels of abstraction
There are four levels of abstraction in metaprogramming that are each a special kind of procedure:
- Ordinary procedures/iterators (No metaprogramming)
- Generic procedures/iterators and typedescs (Type level)
- Template (Copy-paste mechanism)
- Macro (AST substitution)
It is recommended to start to program one's procedure with the lowest level of metaprogramming possible. As more metaprogramming features are used, the compilation process takes longer and error debugging gets harder.
Generics
We often program to perform repetitive tasks easily. Programs must adapt themselves to many cases and might be redundant in a first approach. To limit the scope for debugging, we like to avoid redundancy and let the compiler do code duplication for us. Code duplication means that the generated assembly code has very similar or identical block instructions.
One common example is linear algebra. Imagine you want to perform an addition. Your input data is very general and may as well be integers, floating-point numbers. You do not want to write twice your addition function.
# What to not do!
proc add(x, y: int): int =
return x + y
proc add(x, y: float): float =
return x + y
echo add 2 3
echo add 3.7 4.5Indeed, what if you want to add a function for other types like int32 or float16?
You will have to copy-paste your function, and change the type. Not a problem?
There is nothing in the code telling you how many add functions there is in total.
Whenever a code slip in one of your function, you will have to track all the add functions and fix the bug in all of them.
Generics bring a solution to this:
proc add[T](x,y: T): T =
return x + yLet us start with templates and untyped parameters.
To run each snippet of code in this tutorial, you will need to import the std/macros package.
import std/macrosTemplates
We can see templates as procedures that modify code through a copy-paste mechanism. Pieces of code are given to (and outputted by) the template with a special type : untyped.
For those familiar with preprocessing in the C family of languages (C, C++, C#), it does the same than the #define or #if, #endif macros and much more.
Nim's language defines boolean operator like != with templates. You can even look at Nim's source code, that's almost the same code. See the documentation.
## Example from std/manual
template `!=` (a, b: untyped): untyped =
not (a == b)
doAssert(4 != 5)We can easily repeat code under a custom block. Here duplicate, just duplicate code and repeat takes an additional parameter, an int, as a generalisation of the duplicate template.
Notice that duplicate is not smart. It will repeat any assignment twice in the code's block.
template duplicate(statements: untyped) =
statements
statements
duplicate:
echo 55 5
## Example from Nim In Action
from std/os import sleep
template repeat(count: int, statements: untyped) =
for i in 0 ..< count:
statements
repeat 5:
echo("Hello Templates!")
sleep(100)Hello Templates! Hello Templates! Hello Templates! Hello Templates! Hello Templates!
Do-While keyword
In Nim, there are few restricted keywords and special control-flow mechanisms, as to incite us to create our own constructs (and keep the language simple). Nothing restrains us from defining a doWhile construct similar to languages like C or Javascript.
For those only knowing Nim, this construct enables to run a loop once before testing the condition.
This C code always print Hello World at least once independantly from the start value of the variable i.
int i = 10;
do{
printf("Hello World\n");
i += 1;
}while(i < 10);
We present below two templates that attempt to replicate this construct in Nim. The first one is not guaranteed to work if the loop contains some break or continue keyword.
template doWhileIncorrect(conditional, loop: untyped) =
loop
while conditional:
loop
var iter1 = 0
doWhileIncorrect iter1 < 0:
echo "Hello World"
iter1.incHello World
template doWhile(conditional, loop: untyped) =
var c = true
while c:
defer: c = conditional
loop
var iter2 = 0
doWhile iter2 < 0:
echo "Hello World"
iter2.incHello World
The following code only works with the second template version.
for msg in ["Hello even world", "Goodbye even world"]:
var i = 1
doWhile i < 10:
if i mod 2 != 0:
inc i
continue
echo i, ": ", msg
i += 2With this code we attempt to print messages with only even numbers. The if block ensures
that we do not enter the main part of the while loop body
without an even value in the variable i.
With continue, we go back to the beginning of the loop to ensure that our variable is not greater than 10. With the first template version, the loop is first executed outside of the while loop and continue skip to the next iteration of the for loop instead, effectively skipping all echo statements.
With the keyword defer all the statements are kept inside the while loop.
Notice also that syntaxically the resulting source code is fairly different than the C/C++ code.
In the C source code, appear in this order:
- the
dokeyword - the block of instruction
- the
whilekeyword - the conditional (boolean expression)
In Nim, we have in this order:
- the
doWhileindent - the conditional
- block of instruction
There is no way to modify Nim's syntax as to match C's syntax.
Benchmark example
Another example is benchmarking code in Nim. It suffices to put our bench code inside a special block.
import std/[times, monotimes]
template benchmark(benchmarkName: string, code: untyped) =
block:
let t0 = getMonoTime()
code
let elapsed = getMonoTime() - t0
echo "CPU Time [", benchmarkName, "] ", elapsed
benchmark "test1":
sleep(100)CPU Time [test1] 100 milliseconds, 204 microseconds, and 264 nanoseconds
The code inside the benchmark code block will be enclosed by our template code.
Since the code replacement is done at compile time, this transformation does not add additional runtime to our benchmarked code. On the contrary, a function or procedure for benchmarking would have add runtime due to the nested function calls.
For a lot more robust examples, have a look at the benchy library
Macros
Template uses untyped parameters as lego bricks. It can not break it down into smaller pieces.
We can not check untyped parameters in a template. If our template works when given an object as argument, nothing restrics an user to give a function as argument.
Macros can be seen as an empowered template procedure. While template substitute code, macros do introspection. The main difference is that a template can not look inside an untyped parameter. This means that we can not check the input we get as to verify that the user did not give a function when we expect a type.
One can parse untyped parameters with macros. We can even act something conditionally to informations given in these parameters. We can also inject variables into scopes.
macro throwAway(statements: untyped): untyped =
result = newStmtList()
throwAway:
while true:
echo "If you do not throw me, I'll spam you indefinitely!"AST Manipulation
In Nim, the code is read and transformed in an internal intermediate representation called an Abstract Syntax Tree (AST). To get a representation of the AST corresponding to a code, we can use the macro dumpTree.
# Don't forget to import std/macros!
# You can use --hints:off to display only the AST tree
dumpTree:
type
myObject {.packed.} = ref object of RootObj
left: seq[myObject]
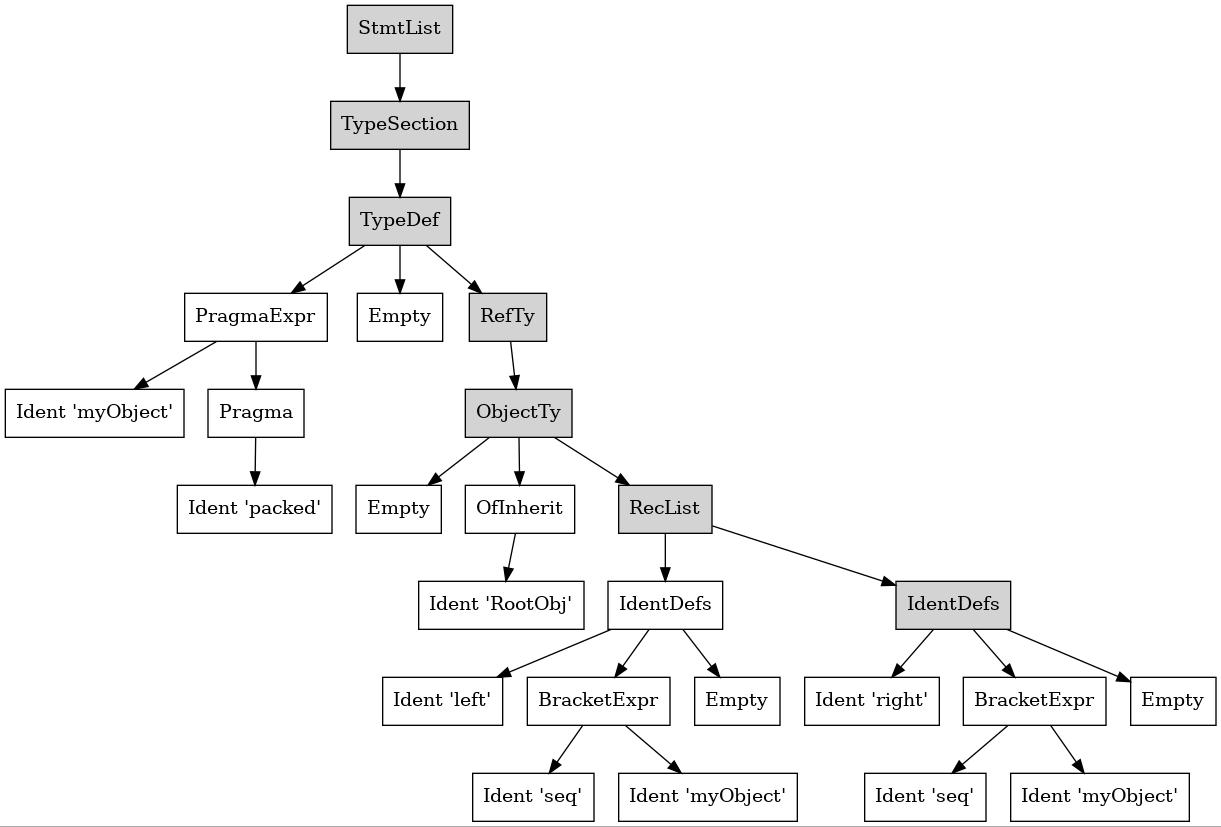
right: seq[myObject]This code outputs the following AST tree (it should not change among Nim versions).
StmtList
TypeSection
TypeDef
PragmaExpr
Ident "myObject"
Pragma
Ident "packed"
Empty
RefTy
ObjectTy
Empty
OfInherit
Ident "RootObj"
RecList
IdentDefs
Ident "left"
BracketExpr
Ident "seq"
Ident "myObject"
Empty
IdentDefs
Ident "right"
BracketExpr
Ident "seq"
Ident "myObject"
Empty
We can better visualize the tree structure of the AST with the following picture.
Multiply by two macro
This example of macro is taken from this Youtube video made by Fireship.
macro timesTwo(statements: untyped): untyped =
result = statements
for s in result:
for node in s:
if node.kind == nnkIntLit:
node.intVal = node.intVal*2
timesTwo:
echo 1
echo 2
echo 32 4 6
This macro multiplies each integer values by two before plotting! Let us breakdown this macro, shall we ? To understand how a macro work, we first may look at the AST given as input.
dumpTree:
echo 1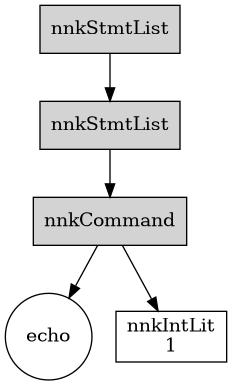
Note: Currently, the automatically generated picture tree adds one extra nnkStmtList node on top. Ignore it.
By compiling this code, you will get the corresponding AST. This simple AST is made of four nodes:
StmtList
Command
Ident "echo"
IntLit 1
StmtList stands for statements list. It groups together all the instructions in your block.
The Command node indicates that you use a function whose name is given by its child Ident node. An Ident can be any variable, object, procedure name.
Our integer literal whose value is 1 has the node kind IntLit.
Notice that the order of the nodes in the AST is crucial. If we invert the two last nodes, we would get the AST of the code 1 echo which does not compile.
StmtList
Command
IntLit 1
Ident "echo"
StmtList, Command, IntLit and Ident are the NodeKind of the code's AST.
Inside your macro, they are denoted with the extra prefix nnk, e.g. nnkIdent.
You can get the full list of node kinds at the std/macros source code.
macro timesTwoAndEcho(statements: untyped): untyped =
result = statements
for s in result:
for node in s:
if node.kind == nnkIntLit:
node.intVal = node.intVal*2
echo repr result
timesTwoAndEcho:
echo 1
echo 2
echo 32 4 6
The output of a macro is an AST, and we can try to write it for a few examples:
StmtList
Command
Ident "echo"
IntLit 2
Command
Ident "echo"
IntLit 4
Command
Ident "echo"
IntLit 6
Please note that line breaks are not part of the Nim's AST!
Here, the output AST is almost the same as the input. We only change the integer literal value.
Our root node in the input AST is a statement list.
To fetch the Command children node, we may use the list syntax.
A Node contains the list of its childrens. To get the first children, it suffices to write statements[0].
To loop over all the child nodes, one can use a for statement in statements loop.
We need to fetch the nodes under a Command instruction that are integer literals.
So for each node in the statement, we test if the node kind is equal to nnkIntLit. We get their value with the attribute node.intVal.
I present down my first macro as an example. I want to print the memory layout of a given type. My goal is to find misaligned fields making useless unocuppied memory in a type object definition. This happens when the attributes have types of different sizes. The order of the attributes then changes the memory used by an object. To deal with important chunks of memory, the processor stores an object and its attributes with some rules.
It likes when adresses are separated by powers of two. If it is not, it inserts a padding (unoccupied memory) between two attributes.
We can pack a structure with the pragma {.packed.}, which removes this extra space. This has the disadvantage to slow down memory accesses.
We would like to detect the presence of holes in an object.
The first step is to look at the AST of the input code we want to parse.
One can look first at the most basic type definition possible, before trying to complexify the AST to get a feeling for the possible edge cases.
dumpTree:
type
Thing = object
a: float32StmtList
TypeSection
TypeDef
Ident "Thing"
Empty
ObjectTy
Empty
Empty
RecList
IdentDefs
Ident "a"
Ident "float32"
Empty
We have to get outputs as much complex as possible to detect edge cases, while keeping the information to the minimum to easily read the AST and locate errors. I present here first some samples of type definition on which I will run my macro.
typeMemoryRepr:
type
Thing2 = object
oneChar: char
myStr: string
type
Thing = object of RootObj
a: float32
b: uint64
c: char
Type with pragmas aren't supported yet
when false: # erroneous code
typeMemoryRepr:
type
Thing {.packed.} = object
oneChar: char
myStr: string
It is not easy (if even possible) to list all possible types. Yet by adding some other informations we can get a better picture of the general AST of a type.
dumpTree:
type
Thing {.packed.} = object of RootObj
a: float32
b: stringStmtList
TypeSection
TypeDef
PragmaExpr
Ident "Thing"
Pragma
Ident "packed"
Empty
ObjectTy
Empty
OfInherit
Ident "RootObj"
RecList
IdentDefs
Ident "a"
Ident "float32"
Empty
IdentDefs
Ident "b"
Ident "string"
Empty
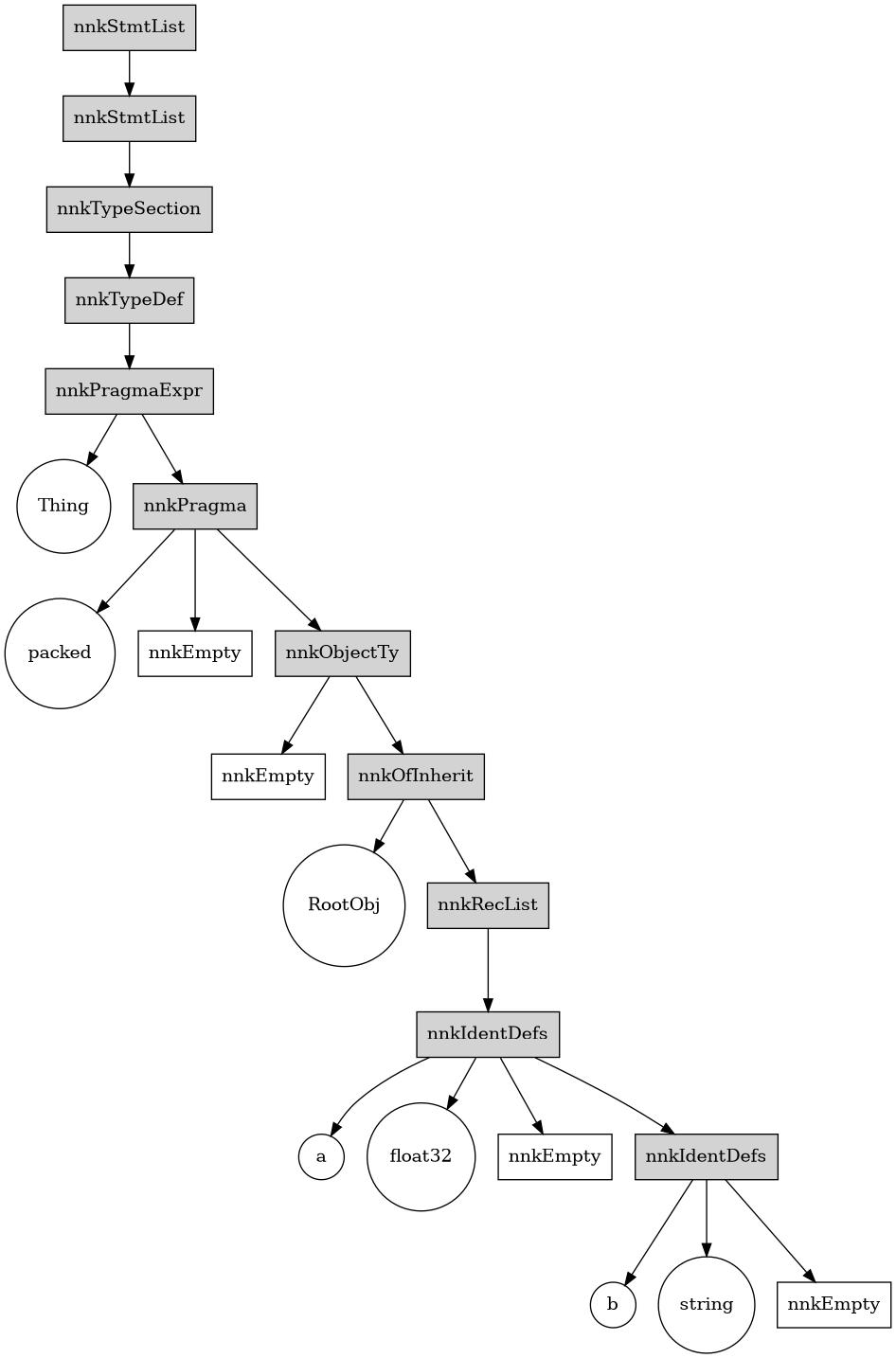
Notice how the name of the type went under the PragmaExpr section. We have to be careful about this when trying to parse the type.
A macro does always the same steps:
- Search for a node of a specific kind, inside the input AST or check that the given node is of the expected kind.
- Fetch properties of the selected node.
- Form AST output in function of these input node's properties.
- Continue exploring the AST.
Your macros will require a long docstring and many comments both with thorough details.
I present now my macro typeMemoryRepr inspired from the nim memory guide on memory representation.
In this guide, we manually print types fields address, to get an idea of the memory layout and the space taken by each variable and its fields.
type Thing = object
a: uint32
b: uint8
c: uint16
var t: Thing
echo "size t.a ", t.a.sizeof
echo "size t.b ", t.b.sizeof
echo "size t.c ", t.c.sizeof
echo "size t ", t.sizeof
echo "addr t.a ", t.a.addr.repr
echo "addr t.b ", t.b.addr.repr
echo "addr t.c ", t.c.addr.repr
echo "addr t ", t.addr.repr
All these echo's are redundant and have to be changed each time we change the type field. For types with more than four or five fields, this becomes not manageable.
I have split this macro into different procedures.
The echoSizeVarFieldStmt will take the name of a variable, let us say a and of its field field and return the code:
echo a.field.sizeof
We create a NimNode of kind StmtList (a statement list), that contains IdentNodes.
The first IdentNode is the command echo.
We do not represent spaces in the AST. Each term separated by a dot is an Ident and part of a nnkDotExpr.
It suffices to output the above code under a dumpTree block, to understand the AST we have to generate.
dumpTree:
echo a.field.sizeof
proc echoSizeVarFieldStmt(variable: string, nameOfField: string): NimNode =
## quote do:
## echo `variable`.`nameOfField`.sizeof
newStmtList(nnkCommand.newTree(
newIdentNode("echo"),
nnkDotExpr.newTree(
nnkDotExpr.newTree(
newIdentNode(variable),
newIdentNode(nameOfField) # The name of the field is the first ident
),
newIdentNode("sizeof")
)
))The echoAddressVarFieldStmt will take the name of a variable, let us say a and of its field field and return its address:
echo a.field.addr.repr
proc echoAddressVarFieldStmt(variable: string, nameOfField: string): NimNode =
## quote do:
## echo `variable`.`nameOfField`.addr.repr
newStmtList(nnkCommand.newTree(
newIdentNode("echo"),
nnkDotExpr.newTree(
nnkDotExpr.newTree(
nnkDotExpr.newTree(
newIdentNode(variable),
newIdentNode(nameOfField)
),
newIdentNode("addr")
),
newIdentNode("repr")
)
))import std/strutilsmacro typeMemoryRepr(typedef: untyped): untyped =
## This macro takes a type definition as an argument and:
## * defines the type (outputs typedef as is)
## * initializes a variable of this type
## * echoes the size and address of the variable
## Then, for each field:
## * echoes the size and address of the variable field
# We begin by running the type definition.
result = quote do:
`typedef`
# Find and validate the type definition
var foundTypeDef = false
var hasFields = false
for statement in typedef:
if statement.kind == nnkTypeSection:
for typeDef in statement:
if typeDef.kind == nnkTypeDef:
foundTypeDef = true
# Validate the structure: TypeDef should have at least 3 children
if typeDef.len < 3:
error("Malformed type definition", typeDef)
# Check if it's an object type with fields
let typeImpl = typeDef[2]
if typeImpl.kind == nnkObjectTy:
# Object types have structure: ObjectTy[pragma, parent, RecList]
if typeImpl.len >= 3 and typeImpl[2].kind == nnkRecList:
if typeImpl[2].len > 0:
hasFields = true
# Report errors if validation failed
if not foundTypeDef:
error("No type definition found in input. " &
"Expected: type MyType = object ...", typedef)
if not hasFields:
error("Type definition must have at least one field. " &
"Example: type MyType = object\n field1: int", typedef)
# Parse the type definition to find the TypeDef section's node
# We create the output's AST along parsing.
# We will receive a statement list as the root of the AST
for statement in typedef:
# We select only the type section in the StmtList
if statement.kind == nnkTypeSection:
let typeSection = statement
for i in 0 ..< typeSection.len:
if typeSection[i].kind == nnkTypeDef:
var tnode = typeSection[i]
# The name of the type is the first Ident child. We can get the ident's string with strVal or repr
let nameOfType = typeSection[i].findChild(it.kind == nnkIdent)
## Generation of AST:
# We create a variable of the given type definition (hopefully not already defined) name for the "myTypenameVar"
let nameOfTestVariable = "my" & nameOfType.strVal.capitalizeAscii() & "Var"
let testVariable = newIdentNode(nameOfTestVariable)
result = result.add(
quote do:
var `testVariable`:`nameOfType` # instanciate variable with type defined in typedef
echo `testVariable`.sizeof # echo the total size
echo `testVariable`.addr.repr # gives the address in memory
)
# myTypeVar.field[i] memory size and address in memory
tnode = tnode[2][2] # The third child of the third child is the fields's AST
assert tnode.kind == nnkRecList
for i in 0 ..< tnode.len:
# myTypeVar.field[i].sizeof
result = result.add(echoSizeVarFieldStmt(nameOfTestVariable, tnode[i][0].strVal))
# myTypeVar.field[i].addr.repr
result = result.add(echoAddressVarFieldStmt(nameOfTestVariable, tnode[i][0].strVal))
echo result.reprtypeMemoryRepr:
type
Thing = object of RootObj
a: float32
b: string32 ptr Thing(a: 0.0, b: "") 4 ptr 0.0 16 ptr ""
typeMemoryRepr:
type Person = object
name: string
age: int24 ptr Person(name: "", age: 0) 16 ptr "" 8 ptr 0
A macro is prone to user misuse. It is therefore crucial to add input validation. The following macro snippets should fail:
typeMemoryRepr:
const x = 5 # No type definition found in input. Expected: type MyType = object ...
typeMemoryRepr:
type Empty = object # Type definition must have at least one field. Example: type MyType = object
# field1: intFor loop
The for loop may be difficult to understand from its dumped tree alone.
for item in 0..10:
echo itemStmtList
ForStmt
Ident "i"
Infix
Ident ".."
IntLit 0
IntLit 10
StmtList
Command
Ident "echo"
Ident "i"
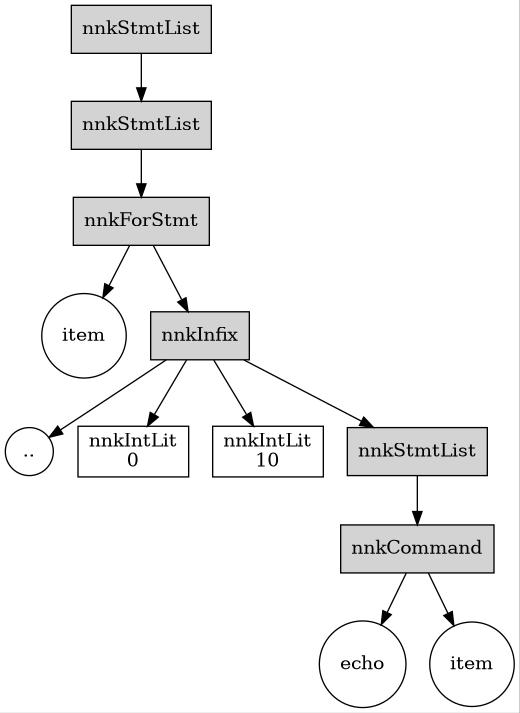
The nnkForStmt has three childrens whose kind may vary.
The first one correspond to the item element, the second to the range or the iterable being looped over, and finally the list of statements in the for block.
# Example 2: For loop iterating over array
dumpTree:
for item in [1, 2, 3]:
echo item
# Example 3: For loop with countdown
dumpTree:
for i in countdown(10, 0):
echo i
# Example 4: For loop with items iterator (explicit)
dumpTree:
for x in items([1, 2, 3]):
echo x
# Example 5: For loop with pairs (index, value)
dumpTree:
for i, val in [10, 20, 30]:
echo i, " -> ", val
# Example 6: For loop with multiple variables (tuple unpacking)
dumpTree:
for (a, b) in [(1, 2), (3, 4), (5, 6)]:
echo a, " and ", b
# Example 7: For loop with three variables
dumpTree:
for (x, y, z) in [(1, 2, 3), (4, 5, 6)]:
echo x, y, z
# Example 8: For loop over string
dumpTree:
for c in "hello":
echo c
# Example 9: For loop with mitems (mutable iterator)
var L = [1, 2, 3]
for item in mitems(L):
item = item * 2
# Example 10: Nested for loops
dumpTree:
for i in 0..2:
for j in 0..2:
echo i, ",", j
# Example 11: For loop with custom iterator call
dumpTree:
for line in lines("file.txt"):
echo line
# Example 12: For loop with inline iterator expression
dumpTree:
for x in @[1, 2, 3]:
echo x
# Example 13: Empty for loop body
dumpTree:
for i in 0..5:
discard
# Example 14: For loop with break/continue
dumpTree:
for i in 0..10:
if i == 5:
break
if i mod 2 == 0:
continue
echo i
# Example 15: For loop with multiple statements in body
dumpTree:
for i in 0..3:
let x = i * 2
let y = x + 1
echo y
# Example 16: For loop with backticks identifier
dumpTree:
for `item value` in [1, 2, 3]:
echo `item value`
# Example 17: For loop with qualified iterator
dumpTree:
for x in system.items([1, 2, 3]):
echo x
# Example 18: For loop using ..< (exclusive range)
dumpTree:
for i in 0..<5:
echo i
# Example 19: For loop with complex tuple pattern
# dumpTree:
# for (i, (x, y)) in [(0, (1, 2)), (1, (3, 4))]:
# echo i, x, y
# Example 20: For loop with type annotation (rare but valid)
# dumpTree:
# for i: int in [1, 2, 3]:
# echo i==========================================
==========================================
StmtList
ForStmt
Ident "item"
Bracket
IntLit 1
IntLit 2
IntLit 3
StmtList
Command
Ident "echo"
Ident "item"
==========================================
==========================================
StmtList
ForStmt
Ident "i"
Call
Ident "countdown"
IntLit 10
IntLit 0
StmtList
Command
Ident "echo"
Ident "i"
==========================================
==========================================
StmtList
ForStmt
Ident "x"
Call
Ident "items"
Bracket
IntLit 1
IntLit 2
IntLit 3
StmtList
Command
Ident "echo"
Ident "x"
==========================================
==========================================
StmtList
ForStmt
Ident "i"
Ident "val"
Bracket
IntLit 10
IntLit 20
IntLit 30
StmtList
Command
Ident "echo"
Ident "i"
StrLit " -> "
Ident "val"
==========================================
==========================================
StmtList
ForStmt
VarTuple
Ident "a"
Ident "b"
Empty
Bracket
TupleConstr
IntLit 1
IntLit 2
TupleConstr
IntLit 3
IntLit 4
TupleConstr
IntLit 5
IntLit 6
StmtList
Command
Ident "echo"
Ident "a"
StrLit " and "
Ident "b"
==========================================
==========================================
StmtList
ForStmt
VarTuple
Ident "x"
Ident "y"
Ident "z"
Empty
Bracket
TupleConstr
IntLit 1
IntLit 2
IntLit 3
TupleConstr
IntLit 4
IntLit 5
IntLit 6
StmtList
Command
Ident "echo"
Ident "x"
Ident "y"
Ident "z"
==========================================
==========================================
StmtList
ForStmt
Ident "c"
StrLit "hello"
StmtList
Command
Ident "echo"
Ident "c"
==========================================
==========================================
StmtList
ForStmt
Ident "i"
Infix
Ident ".."
IntLit 0
IntLit 2
StmtList
ForStmt
Ident "j"
Infix
Ident ".."
IntLit 0
IntLit 2
StmtList
Command
Ident "echo"
Ident "i"
StrLit ","
Ident "j"
==========================================
==========================================
StmtList
ForStmt
Ident "line"
Call
Ident "lines"
StrLit "file.txt"
StmtList
Command
Ident "echo"
Ident "line"
==========================================
==========================================
StmtList
ForStmt
Ident "x"
Prefix
Ident "@"
Bracket
IntLit 1
IntLit 2
IntLit 3
StmtList
Command
Ident "echo"
Ident "x"
==========================================
==========================================
StmtList
ForStmt
Ident "i"
Infix
Ident ".."
IntLit 0
IntLit 5
StmtList
DiscardStmt
Empty
==========================================
==========================================
StmtList
ForStmt
Ident "i"
Infix
Ident ".."
IntLit 0
IntLit 10
StmtList
IfStmt
ElifBranch
Infix
Ident "=="
Ident "i"
IntLit 5
StmtList
BreakStmt
Empty
IfStmt
ElifBranch
Infix
Ident "=="
Infix
Ident "mod"
Ident "i"
IntLit 2
IntLit 0
StmtList
ContinueStmt
Empty
Command
Ident "echo"
Ident "i"
==========================================
==========================================
StmtList
ForStmt
Ident "i"
Infix
Ident ".."
IntLit 0
IntLit 3
StmtList
LetSection
IdentDefs
Ident "x"
Empty
Infix
Ident "*"
Ident "i"
IntLit 2
LetSection
IdentDefs
Ident "y"
Empty
Infix
Ident "+"
Ident "x"
IntLit 1
Command
Ident "echo"
Ident "y"
==========================================
==========================================
StmtList
ForStmt
AccQuoted
Ident "item"
Ident "value"
Bracket
IntLit 1
IntLit 2
IntLit 3
StmtList
Command
Ident "echo"
AccQuoted
Ident "item"
Ident "value"
==========================================
==========================================
StmtList
ForStmt
Ident "x"
Call
DotExpr
Ident "system"
Ident "items"
Bracket
IntLit 1
IntLit 2
IntLit 3
StmtList
Command
Ident "echo"
Ident "x"
==========================================
==========================================
StmtList
ForStmt
Ident "i"
Infix
Ident "..<"
IntLit 0
IntLit 5
StmtList
Command
Ident "echo"
Ident "i"
==========================================
typed Parameters
Hygienic variables
bindSym vs ident
The procedures defined inside macros like helper in the following snippets
are invisible outer m's body.
To call these procedures in the generated code, one has to use a symbol (bound identifier) declared with bindSym. It is similar to ident that declares unbound identifiers.
# Andreas Rumpf "Mastering Nim"
macro m(a: string): untyped =
proc helper(a: string) = echo a
result = newCall(bindSym"helper", a)
m "abc"abc
# Invalid code
macro m(a: string): untyped =
proc helper(a: string) = echo a
result = newCall(ident"helper", a)
m "abc"Avoiding Macros
This section contains an example of a case were using a macro would be tempting but should be avoided by principle of "lesser construct first".
Let's say you want to create enums with power of two as values. You could use the following macro:
import std/[enumerate, math]# jmgomez on Discord
macro power2Enum(body: untyped): untyped =
let srcFields = body[^1][1..^1]
var dstFields = nnkEnumTy.newTree(newEmptyNode())
for idx, field in enumerate(srcFields):
dstFields.add nnkEnumFieldDef.newTree(field, newIntLitNode(pow(2.0, idx.float).int))
body[^1] = dstFields
echo repr body
body
type Test {.power2Enum.} = enum
a, b, c, d
echo $int(c)4
The macro is hard to read but serves the feature. The pragma provides easy to read code, as long as it is well documented.
Yet, there is much simpler by casting elements of a set to uint8. The following snippet illustrates this which leverages the data representation of a set.
Remember: A macro is not always the best construct.
# Rika
type
Setting = enum
a, b, c
Settings = set[Setting]
let settings: Settings = {a, c}
echo cast[uint8](settings)5
References and Bibliography
Press Ctrl + Click to open following links in a new tab.
First, there are four official resources at the Nim's website:
- Nim by Example
- Nim Tutorial (Part III)
- Manual section about macros
- The Standard Documentation of the std/macros library The 2. and 3. documentations are complementary learning resources while the last one will be your up-to-date exhaustive reference. It provides dumped AST (explained later) for all the nodes.
Many developers have written their macro's tutorial:
- Nim in Y minutes
- Jason Beetham a.k.a ElegantBeef's dev.to tutorial. This tutorial contains a lot of good first examples.
- Pattern matching (sadly outdated) in macros by DevOnDuty
- Tomohiro's FAQ section about macros
- The Making of NimYAML's article of flyx
There are plentiful of posts in the forum that are good references:
- What is "Metaprogramming" paradigm used for ?
- Custom macro inserts macro help
- See generated code after template processing
- Fast array assignment
- Variable injection
- Proc inspection
- doWhile improvement
- getType API
- etc … Use the forum search bar with specific keywords like
macro,metaprogramming,generics,template, …
Last but no least, there are three Nim books:
- Nim In Action, ed. Manning and github repo
- Mastering Nim, auto-published by A. Rumpf/Araq, Nim's creator.
- Nim Programming Book, by S.Salewski
We can also count many projects that are macro- or template-based:
-
genny and benchy. Benchy is a template based library that benchmarks your code snippet under bench blocks. Genny is used to export a Nim library to other languages (C, C++, Node, Python, Zig). In general, treeform projects source code are good Nim references
-
My favorite DSL : the neural network domain specific language (DSL) of the tensor library Arraymancer mratsim develops this library, and made a list of all his DSL in the forum.
-
Jester library is a HTML DSL, where each block defines a route in your web application.
-
nimib with which this blog post has been written.
-
Nim4UE. You can develop Nim code for the Unreal Engine 5 game engine. The macro system parses your procs and outputs DLL for UE.